
我院智能计算团队在深度信息估计领域取得新进展
发布时间:2024-12-25阅读数:
场景深度信息对于准确理解空间三维结构关系具有重要意义,在无人智能驾驶、机器人自动避障、即时定位与三维地图重建等任务层面具有广阔的应用前景。传统深度估计算法往往存在泛化能力弱、推理时间长、估计精确度低等问题。随着深度学习的发展和计算机算力的改进,深度信息估计的精度与效率也得到巨大提升。
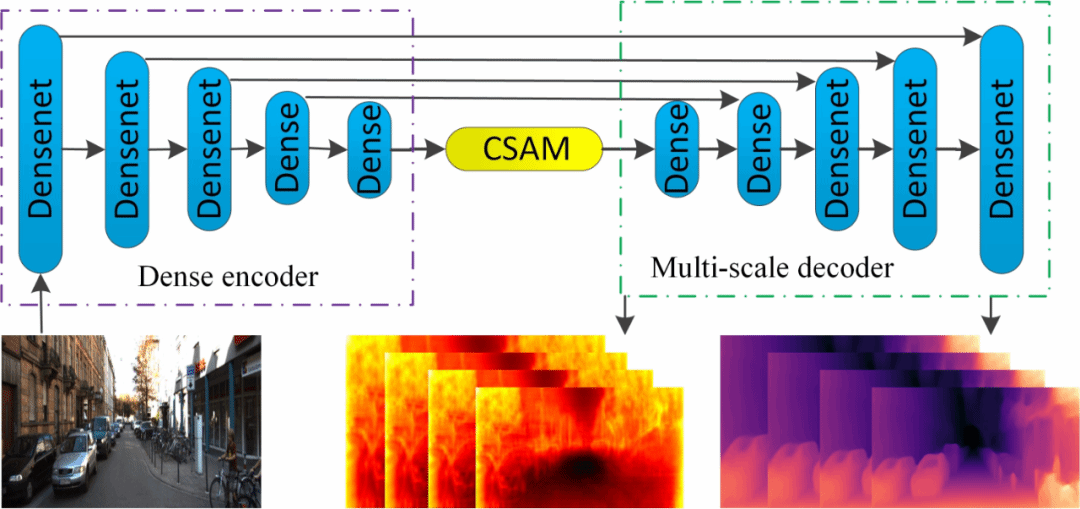
近日,我院智能计算团队柴国强副教授研究组与合作者利用结合运动恢复结构、图像重投影和不确定性理论,以端到端的形式提出一种基于不确定性单目图像自监督深度估计算法。利用基于改进稠密连接模块的编码器-解码器深度估计网络得到目标图像的深度图,利用位姿估计网络计算出拍摄目标图像和源图像2个时刻相机位置转换矩阵;根据图像重投影对源图像进行逐像素采样,得到重构目标图像;结合重构目标函数、不确定性目标函数和平滑目标函数对所提出的网络进行优化训练,通过使重构图像和真实目标图像差异最小化实现自监督的深度信息估计。实验结果表明所提算法在客观指标与主观视觉对比上取得了比CC、Monodepth2、Hr-depth等主流算法更好的深度估计结果。
这一研究成果以“基于不确定性单目图像自监督场景深度估计”为题发表在北京航空航天大学学报[2024,50(12)]。我院柴国强副教授为第一作者,重庆大学刘海军副教授为通讯作者。该工作得到了国家自然科学基金、山西省基础研究计划等项目的资助。

一审:马丽娜
二审:颜志刚
三审:许国宝

